Note: You must have an Expected Parrot account in order to use remote inference and caching. By using remote inference you agree to any terms of use of service providers, which Expected Parrot may accept on your behalf and enforce in accordance with our terms of use.
How it works
When remote inference is activated, calling the run() method on a survey will send it to the Expected Parrot server. Survey results and job details (history, costs, etc.) are automatically stored at the server and accessible from your workspace or at the Jobs page of your account. By default, a remote cache is used to retrieve responses to any questions that have already been run. You can choose whether to use it or generate fresh responses to questions. See the Remote Caching section for more details.Activating remote inference
Log in to your Expected Parrot account and navigate to your Settings page. Enable the Run surveys remotely toggle under Remote Execution: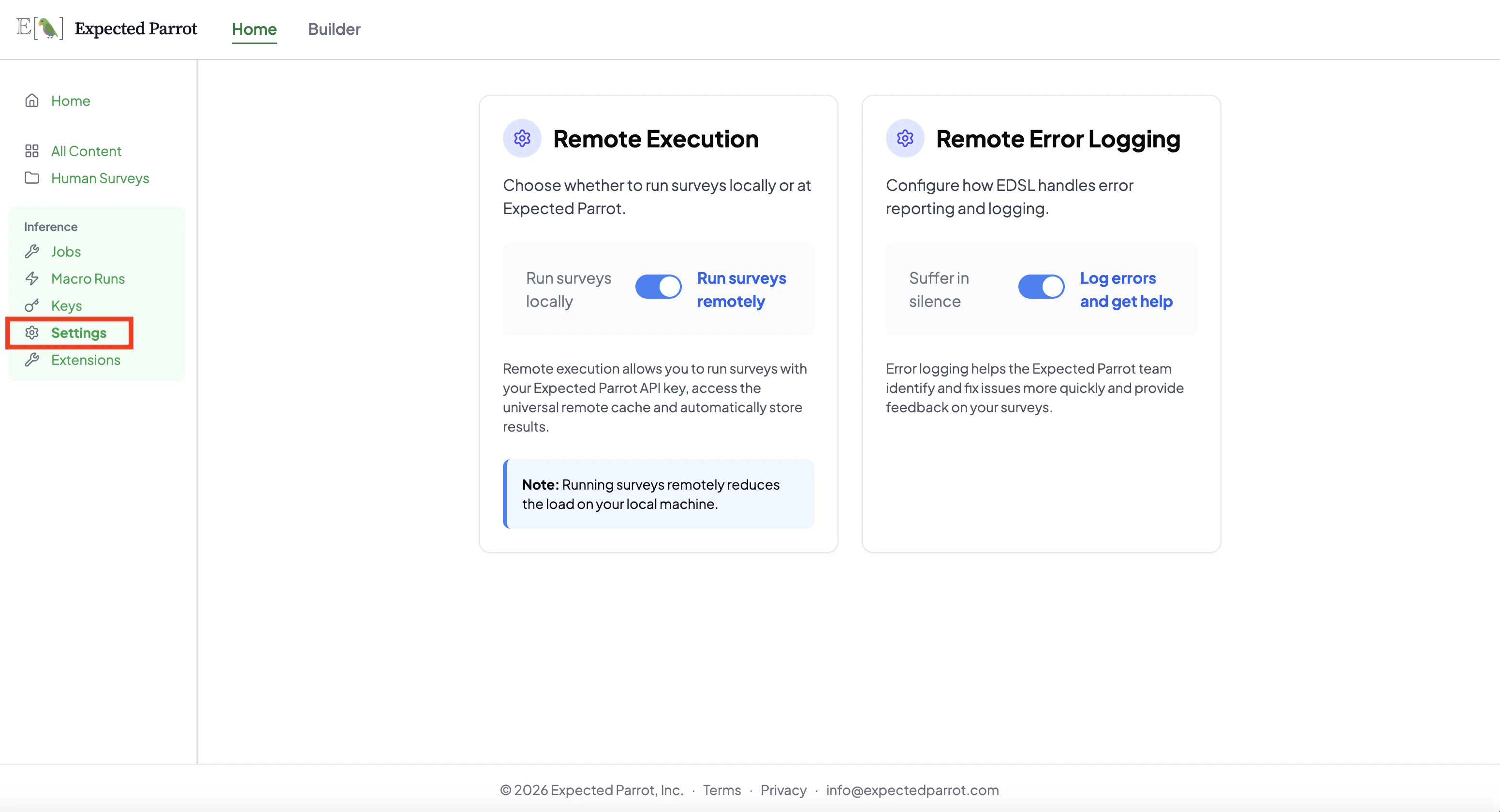
Managing keys
An Expected Parrot key is required to use remote inference and to interact with the platform. Your key can be viewed (and reset) at the Keys page of your account, which also shows the.env format for using it locally:
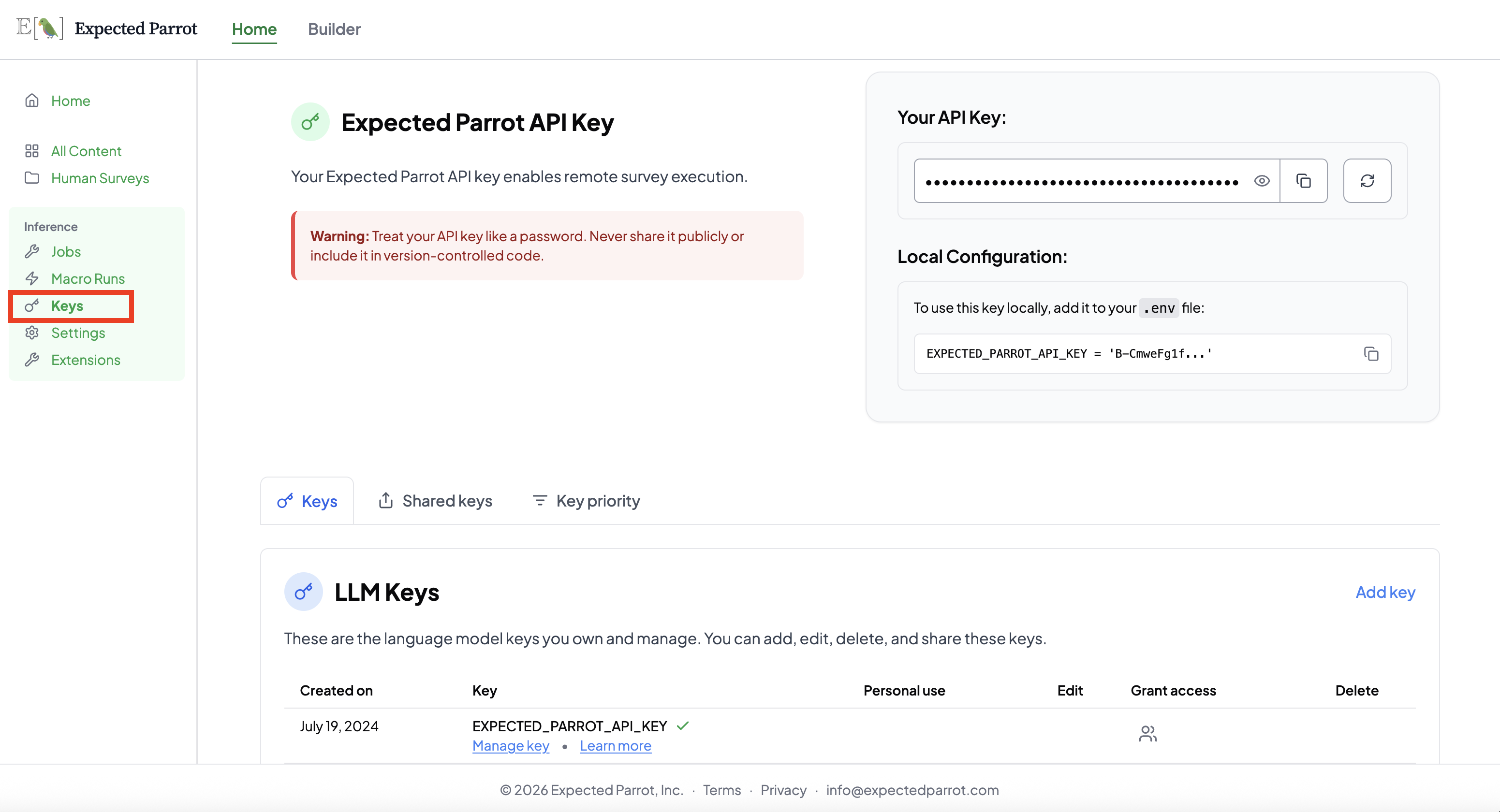
Credits
Running surveys with your Expected Parrot API key requires credits to cover API calls to service providers. Your account comes with free credits for getting started; you can check your balance and purchase additional credits at the Credits page of your account: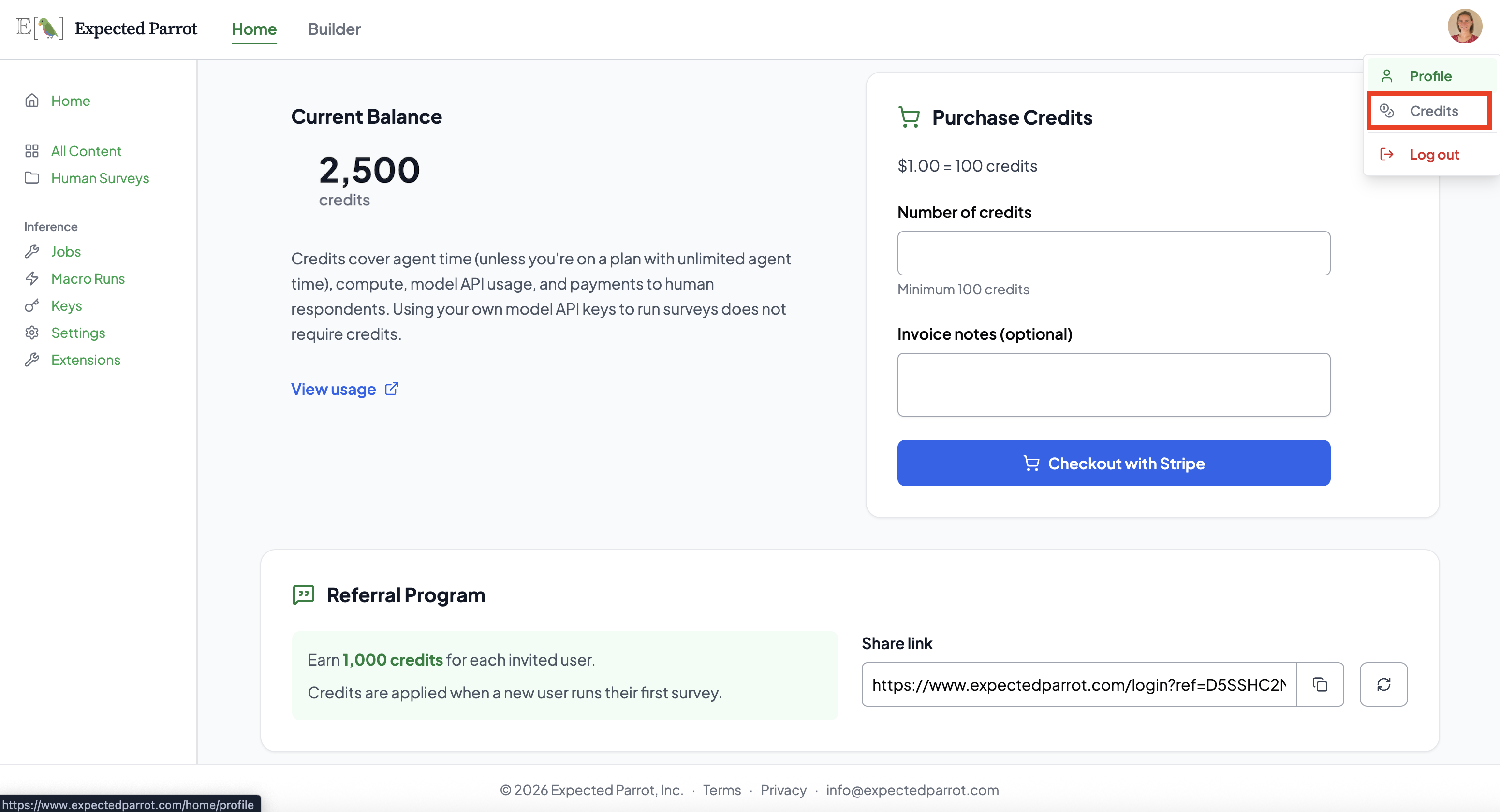
Using remote inference
When remote inference is activated, calling the run() method will send a survey to the Expected Parrot server. You can access results and all information about the job (history, costs, etc.) from your workspace or your Jobs page. For example, here we run a simple survey with remote inference activated and inspect the job information that is automatically posted. We optionally pass description and visibility parameters (these can be edited at any time):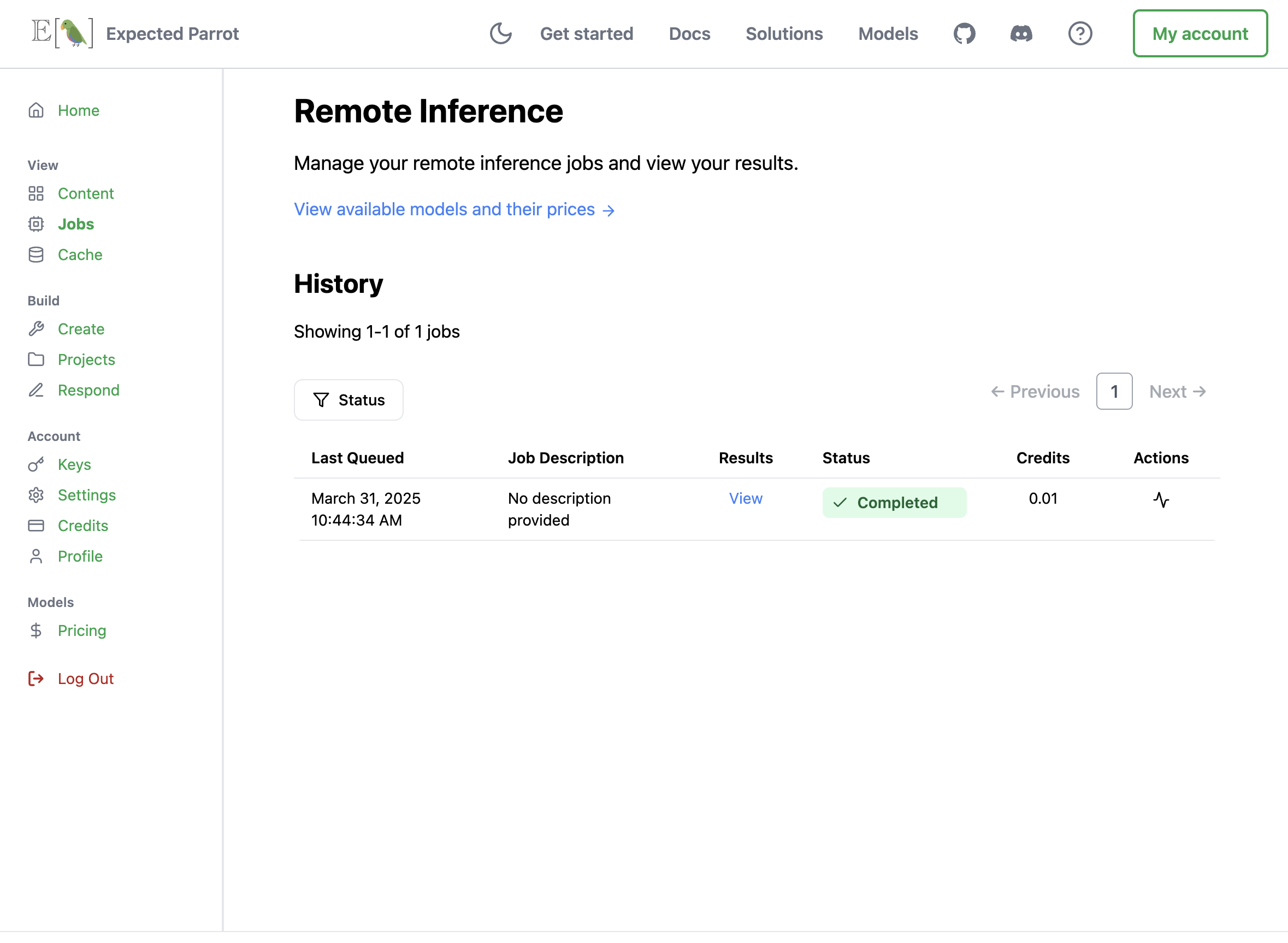
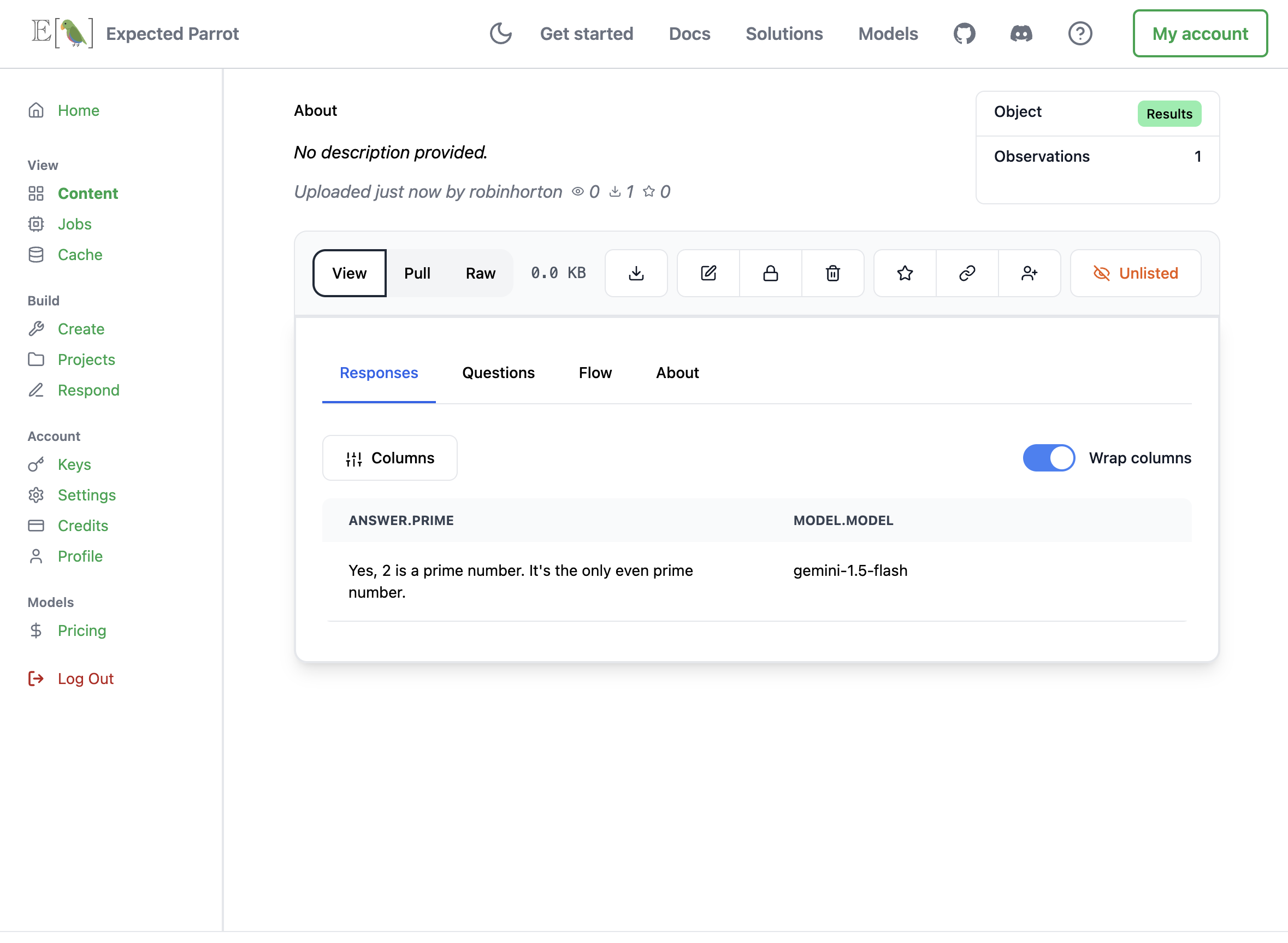
Job details and costs
When you run a job using your Expected Parrot API key you are charged credits based on the number of tokens used. (When you run a job using your own keys you are charged directly by service providers based on the terms of your accounts.) Before running a job, you can estimate the cost of the job by calling the estimate_job_cost() method on the Job object (a survey combined with a model). This will return information about the estimated total cost, input tokens, output tokens and per-model costs: For example, here we estimate the cost of running a simple survey with a model:Coop client object:
Note: When you run a job using your own keys, the cost estimates are based on the prices listed in the model pricing page. Your actual charges from service providers may vary based on the terms of your accounts with service providers.
Job history
You can click on any job to view its history. When a job fails, the job history logs will describe the error that caused the failure. The job history also shows which key was used to run each job (your own key, a key that has been share with you or your Expected Parrot API key):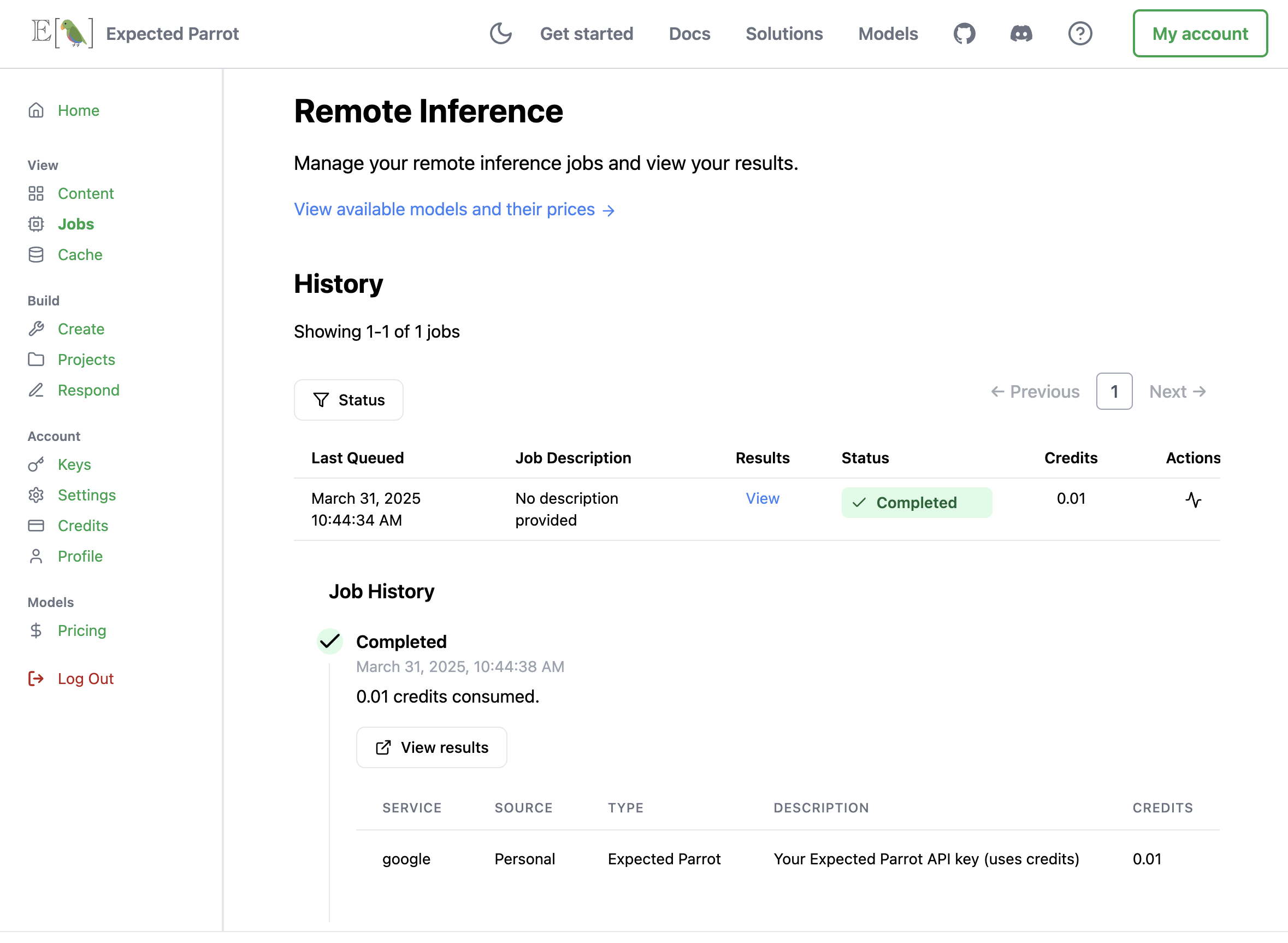
Remote inference methods
Coop class
Bases:class edsl.coop.coop.Coop(api_key: str | None = None, url: str | None = None)[source]
CoopFunctionsMixin
Client for the Expected Parrot API that provides cloud-based functionality for EDSL.
The Coop class is the main interface for interacting with Expected Parrot’s cloud services. It enables:
- Storing and retrieving EDSL objects (surveys, agents, models, results, etc.)
- Running inference jobs remotely for better performance and scalability
- Retrieving and caching interview results
- Managing API keys and authentication
- Accessing model availability and pricing information
Get the estimated cost in credits of a remote inference job. Parameters: input – The EDSL job to send to the server.remote_inference_cost(input: Jobs | Survey, iterations: int = 1) → int[source]
Create a remote inference job for execution in the Expected Parrot cloud. This method sends a job to be executed in the cloud, which can be more efficient for large jobs or when you want to run jobs in the background. The job execution is handled by Expected Parrot’s infrastructure, and you can check the status and retrieve results later.remote_inference_create(job: Jobs, description: str | None = None, status: Literal[‘queued’, ‘running’, ‘completed’, ‘failed’, ‘cancelled’, ‘cancelling’, ‘partial_failed’] = ‘queued’, visibility: Literal[‘private’, ‘public’, ‘unlisted’] | None = ‘unlisted’, initial_results_visibility: Literal[‘private’, ‘public’, ‘unlisted’] | None = ‘unlisted’, iterations: int | None = 1, fresh: bool | None = False) → RemoteInferenceCreationInfo[source]
Parameters:job (Jobs): The EDSL job to run in the cloud description (str, optional): A human-readable description of the job status (RemoteJobStatus): Initial status, should be “queued” for normal use Possible values: “queued”, “running”, “completed”, “failed” visibility (VisibilityType): Access level for the job information. One of:
- “private”: Only accessible by the owner
- “public”: Accessible by anyone
- “unlisted”: Accessible with the link, but not listed publicly
Returns:RemoteInferenceCreationInfo: Information about the created job including:
- uuid: The unique identifier for the job
- description: The job description
- status: Current status of the job
- iterations: Number of iterations for each interview
- visibility: Access level for the job
- version: EDSL version used to create the job
Raises:CoopServerResponseError: If there’s an error communicating with the server
Notes:
- Remote jobs run asynchronously and may take time to complete
- Use remote_inference_get() with the returned UUID to check status
- Credits are consumed based on the complexity of the job
Example:
Get the status and details of a remote inference job. This method retrieves the current status and information about a remote job, including links to results if the job has completed successfully. Parameters: job_uuid (str, optional): The UUID of the remote job to check results_uuid (str, optional): The UUID of the results associated with the job (can be used if you only have the results UUID) include_json_string (bool, optional): If True, include the json string for the job in the responseremote_inference_get(job_uuid: str | None = None, results_uuid: str | None = None, include_json_string: bool | None = False) → RemoteInferenceResponse[source]
Returns:
RemoteInferenceResponse: Information about the job including:job_uuid: The unique identifier for the job results_uuid: The UUID of the results results_url: URL to access the results status: Current status (“queued”, “running”, “completed”, “failed”) version: EDSL version used for the job job_json_string: The json string for the job (if include_json_string is True) latest_job_run_details: Metadata about the job status
interview_details: Metadata about the job interview status (for jobs that have reached running status)total_interviews: The total number of interviews in the job completed_interviews: The number of completed interviews interviews_with_exceptions: The number of completed interviews that have exceptions exception_counters: A list of exception counts for the job exception_type: The type of exception inference_service: The inference service model: The model question_name: The name of the question exception_count: The number of exceptions failure_reason: The reason the job failed (failed jobs only) failure_description: The description of the failure (failed jobs only) error_report_uuid: The UUID of the error report (partially failed jobs only) cost_credits: The cost of the job run in credits cost_usd: The cost of the job run in USD expenses: The expenses incurred by the job run service: The service model: The model token_type: The type of token (input or output) price_per_million_tokens: The price per million tokens tokens_count: The number of tokens consumed cost_credits: The cost of the service/model/token type combination in credits cost_usd: The cost of the service/model/token type combination in USD
Raises:ValueError: If neither job_uuid nor results_uuid is provided CoopServerResponseError: If there’s an error communicating with the server
Notes:
- Either job_uuid or results_uuid must be provided
- If both are provided, job_uuid takes precedence
- For completed jobs, you can use the results_url to view or download results
- For failed jobs, check the latest_error_report_url for debugging information
Example: