Key steps
The key steps to creating and conducting a survey are:1
Create Questions of various types (multiple choice, checkbox, free text, numerical, linear scale, etc.) and combine them in a Survey to administer them together.
2
Optional: Add rules to skip, stop or administer questions based on conditional logic, or pipe context of questions and answers into other questions.
3
Optional: Design personas for AI Agents to answer the questions.
4
Send the survey to language Models of your choice to generate the responses.
Key methods
A survey is administered by calling the run() method on the Survey object, after adding any agents, scenarios and models with the by() method, and any rules or memory with the appropriate methods (see examples of each below):- add_skip_rule() - Skip a question based on a conditional expression (e.g., based on a response to another question).
- add_stop_rule() - End the survey based on a conditional expression.
- add_rule() - Administer a specified question next based on a conditional expression.
- set_full_memory_mode() - Include a memory of all prior questions/answers at each new question in the survey.
- set_lagged_memory() - Include a memory of a specified number of prior questions/answers at each new question in the survey.
- add_targeted_memory() - Include a memory of a particular question/answer at another question in the survey.
- add_memory_collection() - Include memories of a set of prior questions/answers at another question in the survey.
- show_prompts() - Display the user and system prompts for each question in a survey. This is a companion method to the prompts() method of a Job object, which returns a dataset containing the prompts together with information about each question, scenario, agent, model and estimated cost.
- show_rules() - Display a table of the conditional rules that have been applied to a survey.
- show_flow() - Display a graphic of the flow of a survey, showing the order of questions and any rules that have been applied, and any scenarios and/or agent information that has been added.
Piping
You can pipe individual components of questions into other questions, such as inserting the answer to a question in the question text of another question. This is done by using the {{ question_name.answer }} syntax in the text of a question, and is useful for creating dynamic surveys that reference prior answers. Note that this method is different from memory rules, which automatically inlude the full context of a specified question at a new question in the survey: “Before the question you are now answering, you already answered the following question(s): Question: <question_text> Answer: <answer>”. See examples below.Constructing a survey
In the examples below we construct a simple survey of questions, and then demonstrate how to run it with various rules and memory options, how to add AI agents and language models, and how to analyze the results.Importing from Qualtrics
You can import surveys from Qualtrics QSF (Qualtrics Survey Format) files using thefrom_qsf() method:
Defining questions
Questions can be defined as various types, including multiple choice, checkbox, free text, linear scale, numerical and other types. The formats are defined in the Questions module. Here we define some questions by importing question types and creating instances of them:Adding questions to a survey
Questions are passed to a Survey object as a list of question ids:Organizing questions into groups
You can organize questions into logical groups using theadd_question_group() method. This is useful for:
- Analyzing responses by section
- Organizing survey structure
- Visualizing survey flow
Randomizing question options
If your survey includes multiple choice or checkbox questions, you can randomize the order of the options by passing a list of the question names to the questions_to_randomize parameter of the question constructor. For example, here we randomize the order of the options for q1 and q2:Running a survey
Once constructed, a survey can be administered by calling the run() method. If question Scenarios, Agents or Language Models have been specified, they are added to the survey with the by method when running it. (If no language model is specified, the survey will be run with the default model, which can be inspected by running Model().) For example, here we run the survey with a simple agent persona and specify that GPT-4o should be used. Note that the agent and model can be added in either order, so long as each type of component is added at once (e.g., if using multiple agents or models, pass them as a list to the by() method):Job status information
When you run a survey, you will see a table of information about the job status. When the job completes, you can access the Results object that is generated in your workspace and at your account (if the survey is run remotely). You can specify the visibility and description of the results when running a survey remotely by passing the remote_inference_results_visibility and remote_inference_description parameters to the run() method, and modify them at your account at any time. For example, results of the above survey can be viewed at the following page which has been made public: https://www.expectedparrot.com/content/4cfcf0c6-6aff-4447-90cb-cd9e01111a28.Progress Report
While a job is running you can view updates in a Progress Report with details on questions completed, models used and any exceptions generated. If remote inference is activated, a link to a Progress Report will appear automatically in the job status table. If you are running a survey locally, you can pass run(progress_bar=True) to view a report locally.Exceptions Report
If any exceptions are generated you can view details about them in an Exceptions Report, which includes information about the questions, agents, scenarios and models that generated exceptions together with error messages and tracebacks. If remote inference is activated, a link to an Exceptions Report will appear automatically in the job status table. If you are running a survey locally, the report details will appear in your console.Running jobs in the background
If you are running a survey remotely, you can choose to run it in the background by passing the background=True parameter to the run() method:Optional parameters
There are optional parameters that can be passed to the run() method, including:- fresh=False - A boolean value to indicate whether to run the survey with fresh responses (default is False). Example: run(fresh=True) will generate fresh responses for each question.
- n - The number of responses to generate for each question (default is 1). Example: run(n=5) will administer the same exact question (and scenario, if any) to an agent and model 5 times.
- cache - A Cache object to use for caching responses (default is None). Example: run(cache=my_cache) will use the specified cache to store responses.
- disable_remote_inference - A boolean value to indicate whether to run the survey locally while remote inference is activated (default is False). Example: run(disable_remote_inference=True).
- remote_cache_description - A string value to describe the entries in the remote cache when the survey is run remotely. This description will be displayed on the Expected Parrot server and can be used to provide context for the survey. Example: run(remote_cache_description=”This is a survey about local news consumption.”).
- remote_inference_description - A string value to describe the survey when it is run remotely. This description will be displayed on the Expected Parrot server and can be used to provide context for the survey. Example: run(remote_inference_description=”This is a survey about local news consumption.”).
- remote_inference_results_visibility - A string value to indicate the visibility of the results on the Expected Parrot server, when a survey is being run remotely. Possible values are “public”, “unlisted” or “private” (default is “unlisted”). Visibility can also be modified on the platform. Example: run(remote_inference_results_visibility=”public”).
- progress_bar=True - This parameter can be used to view a Progress Report locally. A link to a Progress Report will automatically be provided when you run a survey remotely.
- background=True - This parameter can be used to run a survey in the background, allowing you to continue working (or stop working) while your job completes.
- polling_interval - This parameter can be used to specify the interval (in seconds) at which to check for results when running a survey in the background. The default is 1.0 seconds. Example: run(polling_interval=5.0) will check for results every 5 seconds.
- verbose=True - A boolean value to indicate whether to enable verbose logging (including a table of information about the job that is running) (default is True). Example: run(verbose=False) will disable verbose logging.
Survey rules & logic
Rules can be applied to a survey with the add_skip_rule(), add_stop_rule() and add_rule() methods, which take a logical expression and the relevant questions.Skip rules
The add_skip_rule() method skips a question if a condition is met. The (2) required parameters are the question to skip and the condition to evaluate. Here we use add_skip_rule() to skip q2 if the response to “consume_local_news” is “Never”. Note that we can refer to the question to be skipped using either the id (“q2”) or question_name (“consume_local_news”):Stop rules
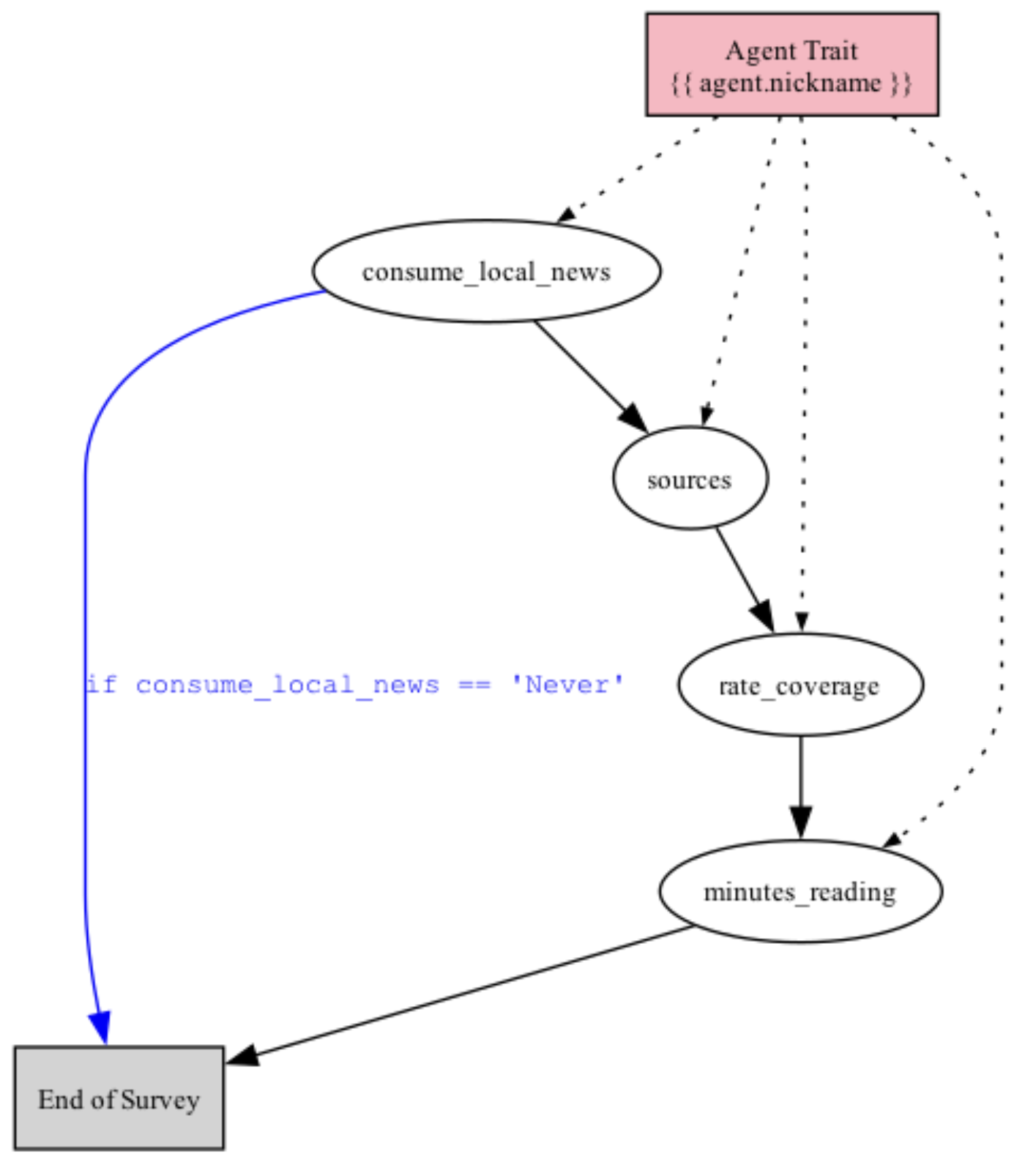
The add_stop_rule() method stops the survey if a condition is met. The (2) required parameters are the question to stop at and the condition to evaluate. Here we use add_stop_rule() to end the survey at q1 if the response is “Never” (note that we recreate the survey to demonstrate the stop rule alone):Other rules
The generalizable add_rule() method is used to specify the next question to administer based on a condition. The (3) required parameters are the question to evaluate, the condition to evaluate, and the question to administer next. Here we use add_rule() to specify that if the response to “color” is “Blue” then q4 should be administered next:Show flow
We can call the show_flow() method to display a graphic of the flow of the survey, and verify how any rules were applied. For example, here we show the flow of the survey above with the skip rule applied: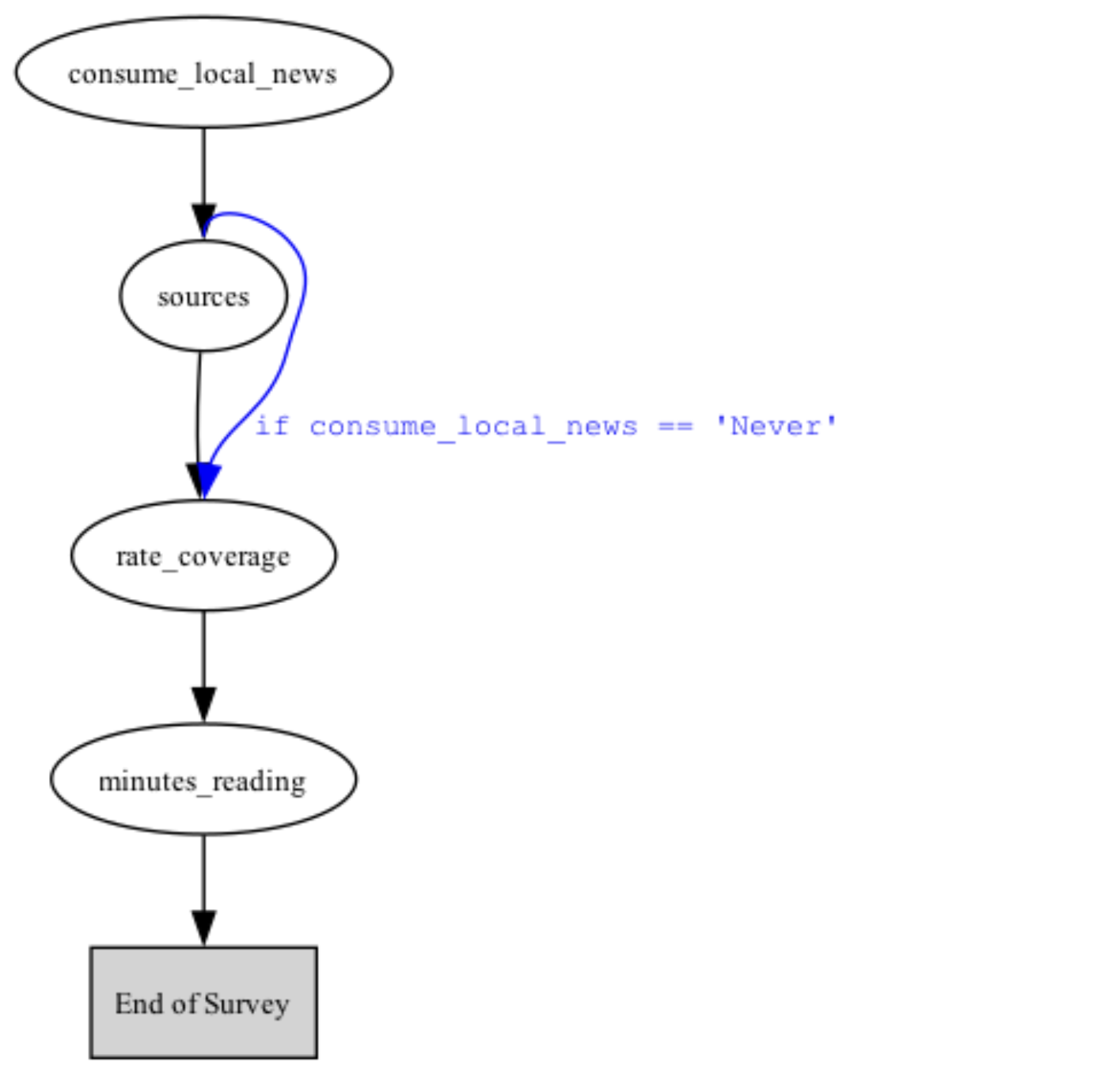
Conditional expressions
The rule expressions themselves (“consume_local_news == ‘Never’”) are written in Python. An expression is evaluated to True or False, with the answer substituted into the expression. The placeholder for this answer is the name of the question itself. In the examples, the answer to q1 is substituted into the expression “consume_local_news == ‘Never’”, as the name of q1 is “consume_local_news”.Piping
Piping is a method of explicitly referencing components of a question in a later question. For example, here we use the answer to q0 in the prompt for q1:
If an answer is a list, we can use the list as the question_options in another question, or index items individually. Here we demonstrate examples of both:
Piping with additional options
In addition to piping answer lists directly asquestion_options, you can use a dict format to pipe options while adding additional static options.
This is useful when you want to include piped options plus additional choices like “None of the above” or “Other”.
The dict format uses two keys:
"from"- A template string referencing the piped options (e.g.,"{{ q1.answer }}")."add"- A list of additional static options to append
The dict format also works when piping from scenario data:
Agent traits
This can also be done with agent traits. For example:Question memory
When an agent is taking a survey, they can be prompted to “remember” answers to previous questions. This can be done in several ways:Full memory
The method set_full_memory_mode() gives the agent all of the prior questions and answers at each new question in the survey, i.e., the first question and answer are included in the memory when answering the second question, both the first and second questions and answers are included in the memory when answering the third question, and so on. The method is called on the survey object:
Note that this is slow and token-intensive, as the questions must be answered serially and requires the agent to remember all of the answers to the questions in the survey. In contrast, if the agent does not need to remember all of the answers to the questions in the survey, execution can proceed in parallel.
Lagged memory
The method set_lagged_memory() gives the agent a specified number of prior questions and answers at each new question in the survey; we pass it the number of prior questions and answers to remember. Here we use it to give the agent just 1 prior question/answer at each question:Targeted memory
The method add_targeted_memory() gives the agent a targeted prior question and answer when answering another specified question. We pass it the question to answer and the prior question/answer to remember when answering it. Here we use it to give the agent the question/answer to q1 when prompting it to answer q4:Memory collection
The add_memory_collection() method is used to add sets of prior questions and answers to a given question. We pass it the question to be answered and the list of questions/answers to be remembered when answering it. For example, we can add the questions/answers for both q1 and q2 when prompting the agent to answer q4:Costs
Before running a survey, you can estimate the cost of running the survey in USD and the number of credits needed to run it remotely at the Expected Parrot server. After running a survey, you can see details on the actual cost of each response in the results. The costs are calculated based on the estimated and actual number of tokens used in the survey and the model(s) used to generate the prompts.Estimated costs
Before running a survey, you can estimate the cost in USD of running the survey by calling the estimate_job_cost() method on a Job object (a survey combined with one or more models). This method returns a dictionary with the estimated costs and tokens for each model used with the survey. You can also estimate credits needed to run a survey remotely at the Expected Parrot server by passing the job to the remote_inference_cost() method of aCoop client object.
Example:
Actual costs
The actual costs of running a survey are stored in the survey results. Details about the cost of each response can be accessed in the raw_model_response fields of the results dataset. For each question that was run, the following columns will appear in results:- raw_model_response.<question_name>_cost: The cost in USD for the API call to a language model service provider.
- raw_model_response.<question_name>_one_usd_buys: The number of tokens that can be purchased with 1 USD (for reference).
- raw_model_response.<question_name>_raw_model_response: A dictionary containing the raw response for the question, which includes the input text and tokens, output text and tokens, and other information about the API call. This dictionary is specific to the language model service provider and may contain additional information about the response.
- The number of input tokens is multiplied by the input token rate set by the language model service provider.
- The number of output tokens is multiplied by the output token rate set by the language model service provider.
- The total cost in USD is converted to credits (1 USD = 100 credits).
- The total cost in credits is rounded up to the nearest 1/100th of a credit.
Survey class
Bases:class edsl.surveys.Survey(questions: List[‘QuestionType’] | None = None, memory_plan: ‘MemoryPlan’ | None = None, rule_collection: ‘RuleCollection’ | None = None, question_groups: ‘QuestionGroupType’ | None = None, name: str | None = None, questions_to_randomize: List[str] | None = None)[source]
Base
A collection of questions with logic for navigating between them.
Survey is the main class for creating, modifying, and running surveys. It supports:
- Skip logic: conditional navigation between questions based on previous answers
- Memory: controlling which previous answers are visible to agents
- Question grouping: organizing questions into logical sections
- Randomization: randomly ordering certain questions to reduce bias
- Instructions: adding non-question elements to guide respondents
Initialize a new Survey instance. This constructor sets up a new survey with the provided questions and optional configuration for memory, rules, grouping, and randomization.init(questions: List[‘QuestionType’] | None = None, memory_plan: ‘MemoryPlan’ | None = None, rule_collection: ‘RuleCollection’ | None = None, question_groups: ‘QuestionGroupType’ | None = None, name: str | None = None, questions_to_randomize: List[str] | None = None)[source]
Args:questions: A list of question objects to include in the survey. Can include QuestionBase objects, Instructions, and ChangeInstructions. memory_plan: Defines which previous questions and answers are available when answering each question. If None, a default plan is created. rule_collection: Contains rules for determining which question comes next based on previous answers. If None, default sequential rules are created. question_groups: A dictionary mapping group names to (start_idx, end_idx) tuples that define groups of questions. name: DEPRECATED. The name of the survey. questions_to_randomize: A list of question names to randomize when the survey is drawn. This affects the order of options in these questions. Examples: Create a basic survey with three questions:
Add an instruction to the survey. Parameters: instruction – The instruction to add to the survey.add_instruction(instruction: Instruction | ChangeInstruction) → Survey[source]
Configure the survey so a specific question has access to multiple prior questions. This method allows you to define memory relationships between specific questions. When an agent answers the focal_question, it will have access to all the questions and answers specified in prior_questions.add_memory_collection(focal_question: QuestionBase | str, prior_questions: List[QuestionBase | str]) → Survey[source]
Args:focal_question: The question for which to add memory, specified either as a QuestionBase object or its question_name string. prior_questions: A list of prior questions to remember, each specified either as a QuestionBase object or its question_name string.
Returns:Survey: The modified survey instance (allows for method chaining).
Examples:When answering q2, remember the answers to both q0 and q1:
Add a question to survey. Parameters:add_question(question: QuestionBase, index: int | None = None) → Survey[source]
- question – The question to add to the survey.
- question_name – The name of the question. If not provided, the question name is used.
Create a logical group of questions within the survey. Question groups allow you to organize questions into meaningful sections, which can be useful for: - Analysis (analyzing responses by section) - Navigation (jumping between sections) - Presentation (displaying sections with headers) Groups are defined by a contiguous range of questions from start_question to end_question, inclusive. Groups cannot overlap with other groups.add_question_group(start_question: QuestionBase | str, end_question: QuestionBase | str, group_name: str) → Survey[source]
Args:start_question: The first question in the group, specified either as a QuestionBase object or its question_name string. end_question: The last question in the group, specified either as a QuestionBase object or its question_name string. group_name: A name for the group. Must be a valid Python identifier and must not conflict with existing group or question names.
Returns:Survey: The modified survey instance (allows for method chaining).
Raises:SurveyCreationError: If the group name is invalid, already exists, conflicts with a question name, if start comes after end, or if the group overlaps with an existing group.
Examples:Create a group of questions for demographics:
Add a conditional rule for navigating between questions in the survey. Rules determine the flow of questions based on conditional expressions. When a rule’s expression evaluates to True, the survey will navigate to the specified next question, potentially skipping questions or jumping to an earlier question. By default, rules are evaluated after a question is answered. When before_rule=True, the rule is evaluated before the question is presented (which is useful for skip logic).add_rule(question: ‘QuestionBase’ | str, expression: str, next_question: ‘QuestionBase’ | str | int | EndOfSurveyParent, before_rule: bool = False) → Survey[source]
Args:question: The question this rule applies to, either as a QuestionBase object or its question_name string. expression: A string expression that will be evaluated to determine if the rule should trigger. Can reference previous questions’ answers using the template syntax, e.g., “{{ q0.answer }} == ‘yes’”. next_question: The destination question to jump to if the expression is True. Can be specified as a QuestionBase object, a question_name string, an index, or the EndOfSurvey class to end the survey. before_rule: If True, the rule is evaluated before the question is presented. If False (default), the rule is evaluated after the question is answered.
Returns:Survey: The modified survey instance (allows for method chaining).
Examples:Add a rule that navigates to q2 if the answer to q0 is ‘yes’:
Add a rule to skip a question based on a conditional expression. Skip rules are evaluated before the question is presented. If the expression evaluates to True, the question is skipped and the flow proceeds to the next question in sequence. This is different from jump rules which are evaluated after a question is answered.add_skip_rule(question: ‘QuestionBase’ | str, expression: str) → Survey[source]
Args:question: The question to add the skip rule to, either as a QuestionBase object or its question_name string. expression: A string expression that will be evaluated to determine if the question should be skipped. Can reference previous questions’ answers using the template syntax, e.g., “{{ q0.answer }} == ‘yes’”.
Returns:Survey: The modified survey instance (allows for method chaining).
Examples:Skip q0 unconditionally (always skip):
Add a rule that stops the survey. The rule is evaluated after the question is answered. If the rule is true, the survey ends. Parameters:add_stop_rule(question: QuestionBase | str, expression: str) → Survey[source]
- question – The question to add the stop rule to.
- expression – The expression to evaluate.
Configure the survey so a specific question has access to a prior question’s answer. This method allows you to define memory relationships between specific questions. When an agent answers the focal_question, it will have access to the prior_question and its answer, regardless of other memory settings.add_targeted_memory(focal_question: QuestionBase | str, prior_question: QuestionBase | str) → Survey[source]
Args:focal_question: The question for which to add memory, specified either as a QuestionBase object or its question_name string. prior_question: The prior question to remember, specified either as a QuestionBase object or its question_name string.
Returns:Survey: The modified survey instance (allows for method chaining).
Examples:When answering q2, remember the answer to q0:
Create a survey with a single question that asks the user how they are doing.classmethod auto_survey(overall_question: str, population: str, num_questions: int) → Survey[source]
Add components to the survey and return a runnable Jobs object. This method is the primary way to prepare a survey for execution. It adds the necessary components (agents, scenarios, language models) to create a Jobs object that can be run to generate responses to the survey. The method can be chained to add multiple components in sequence.by(**args: ‘Agent’ | ‘Scenario’ | ‘LanguageModel’ | ‘AgentList’ | ‘ScenarioList’ | ‘ModelList’*) → Jobs[source]
Args:*args: One or more components to add to the survey. Can include:
- Agent: The persona that will answer the survey questions
- Scenario: The context for the survey, with variables to substitute
- LanguageModel: The model that will generate the agent’s responses
Returns:Jobs: A Jobs object that can be run to execute the survey.
Examples:Create a runnable Jobs object with an agent and scenario:
Remove all non-default rules from the survey.clear_non_default_rules() → Survey[source]
Return the clipboard data for the survey.clipboard_data()[source]
Create the Python code representation of a survey.code(filename: str = ”, survey_var_name: str = ‘survey’) → list[str][source]
Create a codebook for the survey, mapping question names to question text.codebook() → Dict[str, str][source]
Create a deep copy of the survey using serialization. This method creates a completely independent copy of the survey by serializing and then deserializing it. This ensures all components are properly copied and maintains consistency with the survey’s serialization format.copy() → Survey[source]
Returns:Survey: A new Survey instance that is a deep copy of the original.
Examples:
Return the default CSS style for the survey.css()[source]
Return a Directed Acyclic Graph (DAG) representation of the survey flow. This method constructs a DAG that represents the possible paths through the survey, taking into account both skip logic and memory relationships. The DAG is useful for visualizing and analyzing the structure of the survey.dag(textify: bool = False) → DAG[source]
Args:textify: If True, the DAG will use question names as nodes instead of indices. This makes the DAG more human-readable but less compact.
Returns:DAG: A dictionary where keys are question indices (or names if textify=True) and values are sets of prerequisite questions. For example, {2: {0, 1}} means question 2 depends on questions 0 and 1.
Examples:
Delete a question from the survey.delete_question(identifier: str | int) → Survey[source]
Parameters:identifier – The name or index of the question to delete. Returns: The updated Survey object.
DEPRECATED: Usedocx(filename: str | None = None) → FileStore[source]
to_docx() instead.
Return a new survey with a randomly selected permutation of the options.draw() → Survey[source]
Create a new Survey with specified questions removed by name. This method creates a new Survey instance that contains all questions except those specified in the question_names parameter. It’s the inverse of the select() method.drop(*question_names) → Survey[source]
Args:*question_names: Variable number of question names to remove from the survey.
Returns:Survey: A new Survey instance with the specified questions removed.
Raises:ValueError: If no question names are provided. KeyError: If any specified question name is not found in the survey.
Examples:
Duplicate the survey.duplicate()[source]
edit()[source]
Create an example survey for testing and demonstration purposes. This method creates a simple branching survey about school preferences. The default survey contains three questions with conditional logic: - If the user answers “yes” to liking school, they are asked why they like it - If the user answers “no”, they are asked why they don’t like itclassmethod example(params: bool = False, randomize: bool = False, include_instructions: bool = False, custom_instructions: str | None = None) → Survey[source]
Args:params: If True, adds a fourth question that demonstrates parameter substitution by referencing the question text and answer from the first question. randomize: If True, adds a random UUID to the first question text to ensure uniqueness across multiple instances. include_instructions: If True, adds an instruction to the beginning of the survey. custom_instructions: Custom instruction text to use if include_instructions is True.
Defaults to “Please pay attention!” if not provided.
Returns:Survey: A configured example survey instance.
Examples:Create a basic example survey:
Reconstruct a Survey object from its dictionary representation. This class method is the counterpart to to_dict() and allows you to recreate a Survey object from a serialized dictionary. This is useful for loading saved surveys, receiving surveys from other systems, or cloning surveys. The method handles deserialization of all survey components, including questions, instructions, memory plan, rules, and question groups.classmethod from_dict(data: dict) → Survey[source]
Args:data: A dictionary containing the serialized survey data, typically created by the to_dict() method.
Returns:Survey: A fully reconstructed Survey object with all the original questions, rules, and configuration.
Examples:Create a survey, serialize it, and deserialize it back:
Generate a coroutine that navigates through the survey based on answers. This method creates a Python generator that implements the survey flow logic. It yields questions and receives answers, handling the branching logic based on the rules defined in the survey. This generator is the core mechanism used by the Interview process to administer surveys. The generator follows these steps: 1. Yields the first question (or skips it if skip rules apply) 2. Receives an answer dictionary from the caller via .send() 3. Updates the accumulated answers 4. Determines the next question based on the survey rules 5. Yields the next question 6. Repeats steps 2-5 until the end of survey is reachedgen_path_through_survey() → Generator[QuestionBase, dict, None][source]
Returns:Generator[QuestionBase, dict, None]: A generator that yields questions and receives answer dictionaries. The generator terminates when it reaches the end of the survey.
Examples:For the example survey with conditional branching:
Generate a description of the survey.generate_description() → str[source]
Generate a survey from a list of question texts. This method takes a list of question texts and optionally infers question types and generates question names using an LLM.classmethod generate_from_questions(question_texts: List[str], question_types: List[str] | None = None, question_names: List[str] | None = None, model: ‘LanguageModel’ | None = None, scenario_keys: List[str] | None = None, verbose: bool = True) → Survey[source]
Args:question_texts: List of question text strings question_types: Optional list of question types corresponding to each text. If None, types will be inferred by the model. question_names: Optional list of question names. If None, names will be generated. model: Language model to use for inference. If None, uses default model. scenario_keys: Optional list of scenario keys to include in question texts. Each key will be added as {{ scenario.<key> }} in the questions. verbose: Whether to show the underlying survey generation process (default: True)
Returns:Survey: A new Survey instance with the questions
Examples:
Generate a survey from a topic using an LLM. This method uses a language model to generate a well-balanced survey for the given topic with the specified number of questions.classmethod generate_from_topic(topic: str, n_questions: int = 5, model: ‘LanguageModel’ | None = None, scenario_keys: List[str] | None = None, verbose: bool = True) → Survey[source]
Args:topic: The topic to generate questions about n_questions: Number of questions to generate (default: 5) model: Language model to use for generation. If None, uses default model. scenario_keys: Optional list of scenario keys to include in question texts. Each key will be added as {{ scenario.<key> }} in the questions. verbose: Whether to show the underlying survey generation process (default: True)
Returns:Survey: A new Survey instance with generated questions
Examples:
Return the question object given the question name.get(question_name: str) → QuestionBase[source]
get_job(model=None, agent=None, **kwargs)[source]
Run the survey with a gold standard agent and return the result object.gold_standard(q_and_a_dict: dict[str, str]) → Result[source]
Args:q_and_a_dict: A dictionary of question names and answers.
DEPRECATED: Usehtml(scenario: dict | None = None, filename: str | None = None, return_link=False, css: str | None = None, cta: str = ‘Open HTML file’, include_question_name=False) → FileStore[source]
to_html() instead.
Send the survey to Expected Parrot. Then, create a project on Expected Parrot so you can share the survey with human respondents.humanize(project_name: str = ‘Project’, survey_description: str | None = None, survey_alias: str | None = None, survey_visibility: ‘VisibilityType’ | None = ‘unlisted’) → dict[source]
Create an interactive inspector widget for this survey. This method creates a SurveyInspectorWidget that provides an interactive interface for exploring the survey structure, questions, and flow logic.inspect()[source]
Returns:SurveyInspectorWidget instance: Interactive widget for inspecting this survey
Raises:ImportError: If the widgets module cannot be imported
Generate a LaTeX (.tex) representation of the survey.latex(filename: str | None = None, include_question_name: bool = False, standalone: bool = True) → FileStore[source]
Parameters:filename:Optional[str] The filename to write to. If not provided, a temporary file is created in the current working directory with a
.tex suffix.
include_question_name:bool
If True, includes the internal question_name of each question. Default False.
standalone:bool
If True, the LaTeX file is standalone. Default True.
move_question(identifier: str | int, new_index: int) → Survey[source]
Return the next question in a survey.next_question(current_question: str | ‘QuestionBase’ | None = None, answers: Dict[str, Any] | None = None) → ‘QuestionBase’ | EndOfSurveyParent[source]
Parameters:
- current_question – The current question in the survey.
- answers – The answers for the survey so far
- If called with no arguments, it returns the first question in the survey.
- If no answers are provided for a question with a rule, the next question is returned. If answers are provided, the next question is determined by the rules and the answers.
- If the next question is the last question in the survey, an EndOfSurvey object is returned.
Return the next question or instruction in a survey, including instructions in sequence. This method extends the functionality of next_question to also handle Instructions that are interspersed between questions. It follows the proper sequence based on pseudo indices and respects survey rules for question flow.next_question_with_instructions(current_item: str | ‘QuestionBase’ | ‘Instruction’ | None = None, answers: Dict[str, Any] | None = None) → ‘QuestionBase’ | ‘Instruction’ | EndOfSurveyParent[source]
Parameters:
- current_item – The current question or instruction in the survey.
- answers – The answers for the survey so far
- If called with no arguments, it returns the first item (question or instruction) in the survey.
- For instructions, it returns the next item in sequence since instructions don’t have answers.
- For questions, it uses the rule logic to determine the next question, then returns any instructions that come before that target question, or the target question itself.
- If the next item would be past the end of the survey, an EndOfSurvey object is returned.
Returns:Union[“QuestionBase”, “Instruction”, EndOfSurveyParent]: The next question, instruction, or EndOfSurvey.
Examples:With a survey that has instructions:
Return a set of parameters in the survey.property parameters*: set*[source]
Return a dictionary of parameters by question in the survey.property parameters_by_question*: dict[str, set]*[source]
Return a dictionary mapping question names to question indices. Example:property question_name_to_index*: dict[str, int]*[source]
Return a list of question names in the survey. Example:property question_names*: list[str]*[source]
Return a dictionary mapping question names to question attributes.question_names_to_questions() → dict[source]
Check if the question names are valid.question_names_valid() → bool[source]
Return a dictionary of question attributes.question_to_attributes() → dict[source]
A descriptor that manages the list of questions in the survey. This descriptor handles the setting and getting of questions, ensuring proper validation and maintaining internal data structures. It manages both direct question objects and their names. The underlying questions are stored in the protected _questions attribute, while this property provides the public interface for accessing them. Notes:questions[source]
- The presumed order of the survey is the order in which questions are added
- Questions must have unique names within a survey
- Each question can have rules associated with it that determine the next question
classmethod random_survey()[source]
Return a list of questions and instructions (public wrapper). This is a thin wrapper around the internal _recombined_questions_and_instructions method, provided for compatibility with modules that expect a public accessor.recombined_questions_and_instructions() → List[‘QuestionBase’ | ‘Instruction’][source]
Convert the survey to a Job and execute it with the provided parameters. This method creates a Jobs object from the survey and runs it immediately with the provided arguments. It’s a convenient way to run a survey without explicitly creating a Jobs object first.run(*args, **kwargs) → Results[source]
Args:*args: Positional arguments passed to the Jobs.run() method. **kwargs: Keyword arguments passed to the Jobs.run() method, which can include:
- cache: The cache to use for storing results
- verbose: Whether to show detailed progress
- disable_remote_cache: Whether to disable remote caching
- disable_remote_inference: Whether to disable remote inference
Returns:Results: The results of running the survey.
Examples:Run a survey with a test language model:
Execute the survey asynchronously and return results. This method provides an asynchronous way to run surveys, which is useful for concurrent execution or integration with other async code. It creates a Jobs object and runs it asynchronously.async run_async(model: ‘LanguageModel’ | None = None, agent: ‘Agent’ | None = None, cache: ‘Cache’ | None = None, **kwargs) → Results[source]
Args:model: The language model to use. If None, a default model is used. agent: The agent to use. If None, a default agent is used. cache: The cache to use for storing results. If provided, reuses cached results. **kwargs: Key-value pairs to use as scenario parameters. May include:
- disable_remote_inference: If True, don’t use remote inference even if available.
- disable_remote_cache: If True, don’t use remote cache even if available.
Returns:Results: The results of running the survey.
Examples:Run a survey asynchronously with morning parameter:
Return a list of attributes that admissible Scenarios should have. Here we have a survey with a question that uses a jinja2 style {{ }} template:property scenario_attributes*: list[str]*[source]
Create a new Survey with questions selected by name.select(**question_names: List[str]*) → Survey[source]
Configure the survey so agents remember all previous questions and answers. In full memory mode, when an agent answers any question, it will have access to all previously asked questions and the agent’s answers to them. This is useful for surveys where later questions build on or reference earlier responses.set_full_memory_mode() → Survey[source]
Returns:Survey: The modified survey instance (allows for method chaining).
Examples:
Configure the survey so agents remember a limited window of previous questions. In lagged memory mode, when an agent answers a question, it will only have access to the most recent ‘lags’ number of questions and answers. This is useful for limiting context when only recent questions are relevant.set_lagged_memory(lags: int) → Survey[source]
Args:lags: The number of previous questions to remember. For example, if lags=2, only the two most recent questions and answers will be remembered.
Returns:Survey: The modified survey instance (allows for method chaining).
Examples:Remember only the two most recent questions:
Display the survey in a rich format.show()[source]
Show the flow of the survey.show_flow(filename: str | None = None) → None[source]
Display the prompts that will be used when running the survey. This method converts the survey to a Jobs object and shows the prompts that would be sent to a language model. This is useful for debugging and understanding how the survey will be presented. Args: all: If True, show all prompt fields; if False (default), show only user_prompt and system_prompt.show_prompts(all: bool = False) → None[source]
Print out the rules in the survey.show_rules() → None[source]
Simulate the survey and return the answers.simulate() → dict[source]
table(*fields, tablefmt=‘rich’) → Table[source]
Serialize the Survey object to a dictionary for storage or transmission. This method converts the entire survey structure, including questions, rules, memory plan, and question groups, into a dictionary that can be serialized to JSON. This is essential for saving surveys, sharing them, or transferring them between systems. The serialized dictionary contains the complete state of the survey, allowing it to be fully reconstructed using the from_dict() method.to_dict(add_edsl_version: bool = True) → dict[str, Any][source]
Args:add_edsl_version: If True (default), includes the EDSL version and class name in the dictionary, which can be useful for backward compatibility when deserializing.
Returns:dict[str, Any]: A dictionary representation of the survey with the following keys:
- ‘questions’: List of serialized questions and instructions
- ‘memory_plan’: Serialized memory plan
- ‘rule_collection’: Serialized rule collection
- ‘question_groups’: Dictionary of question groups
- ‘questions_to_randomize’: List of questions to randomize (if any)
- ‘edsl_version’: EDSL version (if add_edsl_version=True)
- ‘edsl_class_name’: Class name (if add_edsl_version=True)
Generate a docx document for the survey. This is the preferred alias for the deprecatedto_docx(filename: str | None = None) → FileStore[source]
docx method.
Generate HTML representation of the survey. This is the preferred alias for the deprecatedto_html(scenario: dict | None = None, filename: str | None = None, return_link: bool = False, css: str | None = None, cta: str = ‘Open HTML file’, include_question_name: bool = False) → FileStore[source]
html method.
Convert the survey to a Jobs object without adding components. This method creates a Jobs object from the survey without adding any agents, scenarios, or language models. You’ll need to add these components later using the by() method before running the job.to_jobs() → Jobs[source]
Returns:Jobs: A Jobs object based on this survey.
Examples:
Return a new survey with the questions in long format and the associated scenario list.to_long_format(scenario_list: ScenarioList) → Tuple[List[QuestionBase], ScenarioList][source]
Convert the survey to a scenario list.to_scenario_list(questions_only: bool = True, rename=False) → ScenarioList[source]
tree(node_list: List[str] | None = None)[source]
Turn the survey into a Job and appends the arguments to the Job.using(obj: ‘Cache’ | ‘KeyLookup’ | ‘BucketCollection’) → Jobs[source]
Return a new Survey with the specified question edited. This method creates a new Survey instance with the specified question edited. The new survey inherits relevant attributes from the parent survey but gets fresh rule collections and memory plans appropriate for the subset of questions.with_edited_question(question_name: str, field_name_new_values: dict, pop_fields: List[str] | None = None) → Survey[source]
Return a new survey with a question renamed and all references updated. This method creates a new survey with the specified question renamed. It also updates all references to the old question name in: - Rules and expressions (both old format ‘q1’ and new format ‘{{ q1.answer }}’) - Memory plans (focal questions and prior questions) - Question text piping (e.g., {{ old_name.answer }}) - Question options that use piping - Instructions that reference the question - Question groups (keys only, not ranges since those use indices)with_renamed_question(old_name: str, new_name: str) → Survey[source]
Args:old_name: The current name of the question to rename new_name: The new name for the question
Returns:Survey: A new survey with the question renamed and all references updated
Raises:SurveyError: If old_name doesn’t exist, new_name already exists, or new_name is invalid
Examples: